折腾了一番图像翻译, 耗时若干天, 算是新手上路, 记录下流程.
图像翻译简介(image translation)
简单来说就是把图像A翻译成图像B
Pix2Pix
Pix2Pix利用卷积神经网络和生成对抗方法做图像翻译的经典项目, 发布于2017年, 运行环境要求低, 结构清晰很适合新手入门.
本次使用的是github上的pix2pix-tensorflow项目
.
确定基本流程
本案例的目标是用手绘的线条生成稻妻风格的海景图片 .

分析需求
为了实现上述流程:
1.使用Pix2Pix模型
2.制作模型需要的训练数据(每个样本都是一对黑白线框与彩图)
运行环境搭建
硬件
gpu: gtx 970 4G
注: 这里只写gpu的原因是使用cpu运行深度学习类的模型效率上令人无法接受. 正经人可以排除使用cpu运行的可能性
系统
windows 10 64x
软件
- conda 4.10.3 (理论上最新版就行)
- python 3.8.10 (理论上只要是python3就行)
Pix2Pix-tensorflow的conda运行环境
由于是比较古老的项目, 说明文件中要求使用tensorflow 1.4.1, 对应的gpu版在anaconda镜像源里是没有的, 实际上使用最新tensorflow1也可以正常运行模型.
新建conda环境
1 | conda create -n tf1 python=3.8 |
注: 退出环境的命令是: conda deactivate
安装tensorflow-gpu
1 | conda install tensorflow-gpu=1 |
注: 能用conda安装的包尽量用conda, 会少踩不少坑
注2: 如果已经安装了tensorflow2, 无需卸载, 可以修改pix2pix.py代码中的tensorflow导入部分:
1 | #import tensorflow as tf |
用于数据预处理的环境
对图像数据处理比较常用opencv, 此外如果需要更好的翻译效果还会用到语义分割(此案例中不涉及).
安装python-opencv
采用opencv官方文档的安装方式(手动安装)
1.安装支持包
1 | conda install numpy matplotlib |
2.从github下载安装包
opencv-4.5.3-vc14_vc15.exe
并双击解压到c:/opencv/
这个安装过程实际上只是解压了运行文件, 并没有往系统里加东西
3.添加环境变量
将opencv安装目录下的build/x64/vc15/bin这个目录添加到系统环境变量path中(不添加环境变量的话会出现找不到dll之类的错误)
4.复制python包
拷贝opencv安装目录下的build/python/cv2这个文件夹到python的site-packages目录.
注: 如果找不到site-packages目录可以在python中引入一个包后print出包的路径.
1 | import numpy |
安装jupyter notebook(可选)
使用jupyter notebook可以在图像处理方案调整的过程中比较方便地看到结果.
1 | conda import jupyter |
样本
样本处理的过程需要将原始的游戏截图, 经裁剪缩放成256x256大小的三通道彩图, 从原图中生成轮廓图, 并与原图拼接在一起, 以满足pix2pix模型的需求.
原始图像采集
利用原神自带的拍照功能, 屏蔽角色和个人信息, 就能得到类似下面的原始素材.
预处理
对原始图像素材的处理主要使用opencv, 实际处理过程是批量进行的, 此处以一个样例切入记录处理过程的细节.
先引入一些必要的包并载入样例图片
1 | import cv2 |
裁剪
首先每张原图右下角都有一个”原神”logo, 可能影响训练效果, 先裁剪掉, 保留下的图如黄框所示
1 | 剪掉水印 = test_img[0:1440,0:2208] # 原图尺寸(1440, 2560, 3) |
此后可以提取出若干张长宽1:1的图如区块1,2所示, 每个区块实际上会有部分重叠, 这样就构造了训练样本的平移不变性
1 | def 水平拆分(im, 移动=0.1): |

缩放
原本的图片分辨率过高, 超出了我们所能承担的硬件环境, 需要把它们缩小到256x256的尺寸
1 | 目标输出样例 = cv2.resize(正方形图片,(256,256)) |

生成边界
我们的目标是手绘线条来生成图片, 那么除了有作为输出的目标图片, 还需要有与之对应的线条.
目前很多生成图片的项目采用语义图来生成而非线条, 因为语义图可以包含较多的有效信息, 并且比较符合人类的认知.
不过在不能破解原神的前提下, 生成语义图的过程需要比较多的人工标注.
这里我们比较懒就不用语义图, 而是采用比较方便快捷的canny边缘检测算子.
由于是彩图, 我们对三个通道分别计算边缘并且合并.
1 | def canny(im, sigma=0.3): |
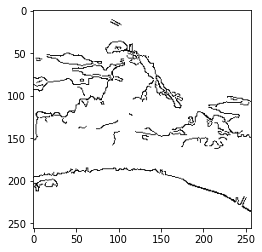
上述得出的边缘比较细, 可以简单加粗使其看起来更像手绘
1 | m1 = np.float32([[1,0,0],[0,1,1]]) |

合成训练样本
样本构造的最后一步是将上面生成的目标输出样例和目标输入样例拼接成一张图
1 | 画布 = np.float32([[1,0,aeg.shape[0]],[0,1,0]]) |

训练模型时选择BtoA模式(左半边为A图, 右半边为B图)
训练Pix2Pix模型
训练
如果需要用部分样本测试, 可以使用pix2pix-tensorflow项目提供的样本划分工具进行划分
1 | python tools/split.py --dir dqhj |
split.py会将--dir指向的目录中的样本划分为train(训练集)和val(测试集)
将生成的一系列训练样本放在与pix2pix.py同目录的dqhj_train文件夹下
使用命令提示符(cmd)路径到对应目录运行
1 | python pix2pix.py --mode train --output_dir dqhj_ckt --max_epochs 200 --input_dir dqhj_train --which_direction BtoA |
使用默认参数训练, gtx970 大约每秒5~6个样本, 可以据此预估时间, 训练过程中也会实时显示剩余分钟数.
这里几个比较重要的参数,
–mode: 运行的模式主要有train, test, export
–output_dir: 训练模型的输出目录
–max_epoches: 模型训练的最大迭代周期数(完整跑完一遍训练样本算一个周期)
–input_dir: 训练样本所在的目录
–which_direction: 训练样本所对应的输入和输出位置, 输入在左输出在右则选择AtoB, 反之选择BtoA
此外,
–batch_size: 为每一步使用的样本数量, 默认为1, 如果显存足够大可以适当增加以提高训练效率
–separable_conv: 设置为true则表示使用深度可分的卷积层代替默认卷积层, 在多数情况下可以减小训练出的生成器体积.
更多参数参可以查看pix2pix.py源码, 这里就不一一列举.
导出生成器
由于pix2pix的核心是一个生成对抗网络, 初步训练得到的模型里包含了生成器(generator)和判别器(discriminator), 模型文件比较大.
接下来的部署只需要保留生成器. 用pix2pix的export模式将其导出
1 | python pix2pix.py --mode export --output_dir dqhj_export --checkpoint dqhj_ckt |
这里的--checkpoint参数需要填入训练出的模型目录
如果正确导出--output_dir对应的目录中将包含如下文件:
在服务器上简单部署
模型文件的使用
部署之前, 有必要了解前面导出的生成器模型的使用方式.
pix2pix-tensorflow源码中导出内容采用了checkpoint方式.
导入模型时需要先导入meta-graph生成图, 而后恢复保存的参数.
1 | modeldir = r"dqhj_export" |
模型提供了输入和输出接口, 可以通过如下语句获得
1 | import json |
模型的输入格式为图片文件base64编码的web_save模式(用-和_替换了原始base64编码中的+和/).
输出同样是图片文件base64编码的web_save模式.
用一个样本测试模型能否正常工作:
1 | f = open('n1-inputs.png', 'rb') |
web后端结构
tensorflow官方有一个tensorflow-serve项目用于tensorflow模型的部署, 然而它的文档被墙了. 所以我们不使用这个工具.
为了实现在服务器上调用我们需要为这个应用设计一个基本结构:
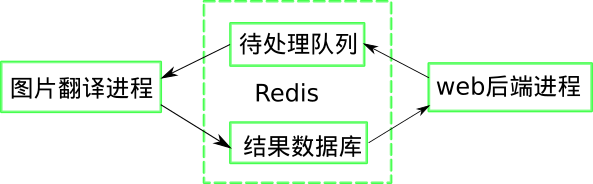
简单来说就是web后端接收数据并推入待处理队列, 图片翻译进程以此处理队列数据并将结果返回到数据库, web后端通过查询数据库获取结果返回.
我们预计并发数不会太高, 可以用一个Redis数据库搞定队列和结果存储的功能.
web前端
前端基本就是做一个界面没啥好说的, 值得注意的是图片文件转base64编码的问题.
我们使用npm上的js-base64
开源项目, 转换图片文件之前先将图片文件转为Uint8Array形式, 才能正确编码, 且编码后需要替换掉+和/.